干货 PostgreSQL数据表文件底层结构布局分析 - 知乎
1. 表文件
PostgreSQL提供了可靠、稳定、有序的数据存储、检索管理。即使在不知道其背后运行原理的情况下,也没有多大关系,因为我们只需要按部就班地执行建库、建表然后插入数据结构这几个流程,就可以如愿以偿地实现将我们的数据持久化于PostgreSQL数据库中。于是我们不得不好奇,这些数据最终落盘于磁盘上的哪个位置?又是以什么样的形式存储?存储的格式又是什么?在这几个疑问的驱动下,本文将通过源码结合数据入库实践操作的方式,来详细地对PostgreSQL底层数据的存储方式进行详细的解读。
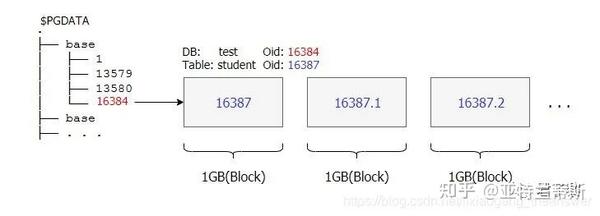
PostgreSQL中的每个表(TABLE)都将由一个或多个堆文件表示。默认情况下,表的每个1GB块(Block)存储在一个单独的(堆)文件中。当该表文件已经达到1GB之后,用户再次插入数据时,postgres会重新创建一个新的堆文件,新文件名格式是:表Oid +“.” + 序号id(序号id从1开始一次递增)。示意图如下所示,其中tudent为CREATE TABLE创建的表名,该student表对应的堆文件名是16387。
在PostgreSQL中,数据库名和表文件名都是使用Oid来进行命名。该Oid是一个无符号整型(unsigned int),定义在postgres_ext.h文件中。如下:
/*
* Object ID is a fundamental type in Postgres.
*/
typedef unsigned int Oid;
当我们将数据存储在PostgreSQL中时,PostgreSQL会将用户插入(INSERT INTO)的数据依次存储于文件系统的常规文件中。对于这样的文件,我们称之为“堆文件(Heap File)”。在PostgreSQL中,可以将堆文件分为四种类型:“普通堆文件(Ordinary Cataloged Heap)、“临时堆文件(Temporary Heap File)、“序列堆文件(Sequence File)和“TOAST表堆文件(TOAST FILE)”。上面说的常规文件,即指普通堆文件。TOAST文件专门用于存储变长数据,本质上它也是属于普通堆文件。对于上面的这四种堆文件,虽然底层组织方式细节不大一样,但是结构上是相似的,所以我们这里将着重分析普通堆文件。
1.2 数据蔟目录位置
在研究表文件之前,我们先要知道postgres的数据蔟目录位置。因为所有的数据库、表、索引、配置文件等等都是存储在数据蔟目录下的,即PGDATA。如果你不确定当前环境上面PostgreSQL的数据蔟目录位置,没关系,你仅需要psql登录终端,然后执行 SHOW DATA_DIRECTORY;命令即可得到。如下图所示,当前环境的数据蔟目录是:/home/lixiaogang5/DB。
test=#
test=# SHOW DATA_DIRECTORY;
data_directory
----------------------
/home/lixiaogang5/DB
(1 row)
test=#
1.3 表文件位置
对于关系型数据库,所有的表都是以库为维度进行管理,即某个表总是属于某个库。因此,我们还需要找到我们创建的数据库(CREATE DATABASE;)以及该库下的所有表(CREATE TABLE)。PostgreSQL为我们提供了pg_relation_filepath,用于查找指定表名的相对($PGDATA)文件路径。
test=#
test=# SELECT pg_relation_filepath('student');
pg_relation_filepath
----------------------
base/16384/16387
(1 row)
test=#
如上图所示,其中16384是数据库(test)的Oid名;16387是student数据表名。其数据库和数据表的创建过程如下:
postgres=# CREATE DATABASE test;
CREATE DATABASE
test=#
test=# CREATE TABLE student(id SERIAL PRIMARY KEY, name VARCHAR, age INT NOT NULL);
CREATE TABLE
2. 表文件的内部布局
前面创建了名为student的数据表,到此为止,还没有向该表中插入(INSERT INTO)过数据。因此student表的总行数是0。
test=# SELECT COUNT(*) FROM student;
count
-------
0
(1 row)
注:关系数据表中的行数据称为记录(record),又称之为元组(tuple),即行、记录、元组都是同一个概念。
在表中没有数据时,很显然此时文件大小是0字节。如下图中红色字体所示:

现在我们向该表中插入一条数据,如下:
test=# SELECT COUNT(*) FROM student;
count
-------
0
(1 row)
test=# INSERT INTO student(name,age) VALUES ('lixiaogang5', 27);
INSERT 0 1
test=# SELECT *FROM student;
id | name | age
----+-------------+-----
1 | lixiaogang5 | 27
(1 row)
test=#
此时再次查看该student数据表文件时,可看到其文件大小是8KB(8192Byte)。很显然,我们刚插入的这条数据并没有这么大。因此可知,postgres在向表中插入数据时候是以8KB为单位进行数据存储管理的。第一次数据进来,无论数据多少,postgres都会在该文件中分配8KB的空间 。
[root@Thor 16384]# ls -lh --full-time 16387
-rw------- 1 postgres postgres 8.0K 2021-05-22 15:05:55.223806439 +0800 16387
2.1 表文件由页组成
对于PostgreSQL数据库,在每个数据文件(堆文件、索引文件、FSM文件、VM文件等)内部,它分为固定长度的页(或块)。换言之,即一个1GB大小的表文件内部是有若干个固定的页组成。页的默认大小为8192字节(8KB)。单个表文件中的这些页(Page)从0开始进行顺序编号,这些编号也称为“块编号(Block Numbers)”。如果第一页空间已经被数据填满,则postgres会立刻重新在文件末尾(即已填满页的后面)添加一个新的空白页,用于继续存储数据,一直持续这个过程,直到当前表文件大小达到1GB位置。若文件达到1GB,则重新创建一个新的表文件,然后重复上面的这个过程。
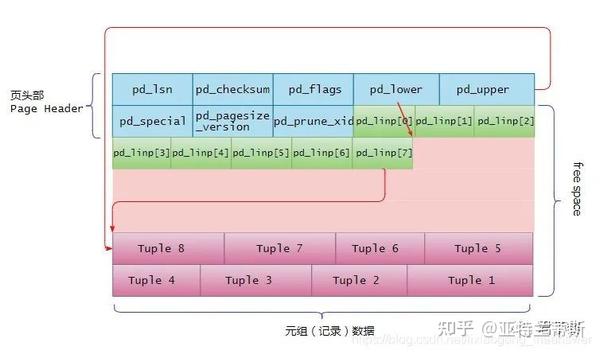
然后每个页的内部又由一个页文件头(Page Header)、若干行指针(Line Pointer)、若干个元组数据(Heaple Tuple)组成。单个文件大小1GB(默认,可以修改其大小),因为堆(重点将普通堆)文件是由页组成,所以可知一个堆文件中有:1GB = (1024 * 1024) KB / 8KB(Page) = 131072个页。
2.1.1 页的内部布局
堆表文件的内部页布局示意图如下:
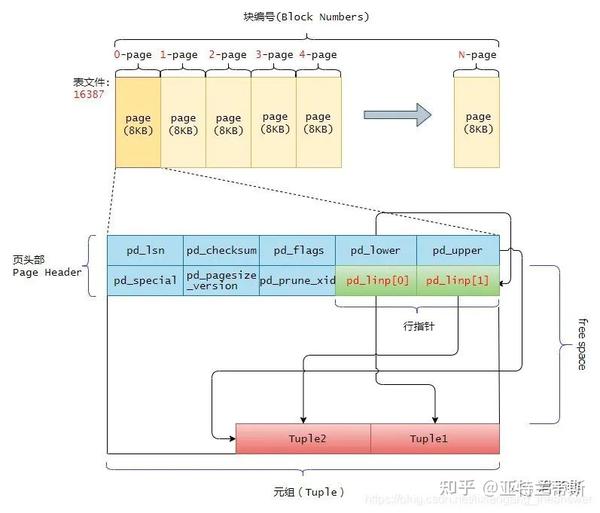
下面分别对页中的“页头、行指针和堆元组”这三个重要数据进行介绍。
2.1.1.1 页头部数据结构
页头数据结构(PageHeaderData)声明于文件bufpage.h中,它包含了当前页的常规信息。其大小是24字节(byte),且分配在页的开头位置。其声明格式如下:
typedef struct PageHeaderData
{
/* XXX LSN is member of *any* block, not only page-organized ones */
PageXLogRecPtr pd_lsn; /* LSN: next byte after last byte of xlog
* record for last change to this page */
uint16 pd_checksum; /* checksum */
uint16 pd_flags; /* flag bits, see below */
LocationIndex pd_lower; /* offset to start of free space */
LocationIndex pd_upper; /* offset to end of free space */
LocationIndex pd_special; /* offset to start of special space */
uint16 pd_pagesize_version;
TransactionId pd_prune_xid; /* oldest prunable XID, or zero if none */
ItemIdData pd_linp[FLEXIBLE_ARRAY_MEMBER]; /* line pointer array [行指针数组]*/
} PageHeaderData;
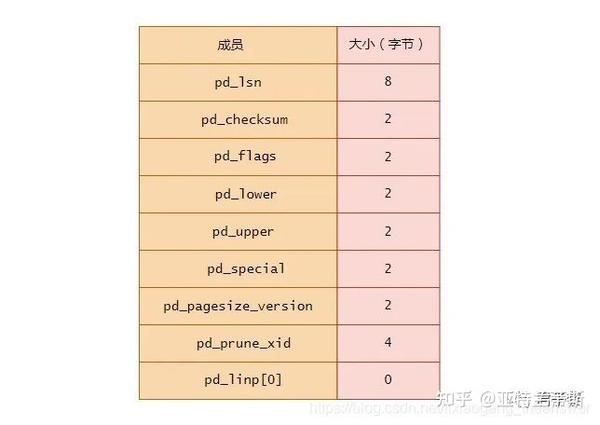
以下是该数据结构中各成员成员的功能描述:
· pd_lsn
pd_lsn变量存储由本页最后一次更改所写入的XLOG记录的LSN(即当前WAL位置)。它是一个8字节的无符号整数,与WAL(Write-Ahead Logging)机制有关。其中PageXLogRecPtr数据类型的声明如下:
typedef unsigned int uint32; /* == 32 bits */
typedef struct
{
uint32 xlogid; /* high bits */
uint32 xrecoff; /* low bits */
} PageXLogRecPtr;
· pd_checksum
此变量存储此页的校验和值(请注意,9.3或更高版本支持此变量;在早期版本中,此部分存储了页面的timelineId)。如果checksum已启用,则为每个数据页计算校验和。检测到校验和失败将导致读取数据时出错,并将中止当前正在运行的事务。因此,这为直接在数据库服务器级别检测I/O或硬件问题带来了额外的控制。
· pd_flags
该成员用以设置位标志。对于PostgreSQL 13.2版本,共支持以下几种标志:
//是否有未使用的行指针?
#define PD_HAS_FREE_LINES 0x0001
//没有足够的空间容纳新元组?
#define PD_PAGE_FULL 0x0002
//页面上的所有元组对每个人都可见?
#define PD_ALL_VISIBLE 0x0004
//所有有效pd_flags位的OR
#define PD_VALID_FLAG_BITS 0x0007
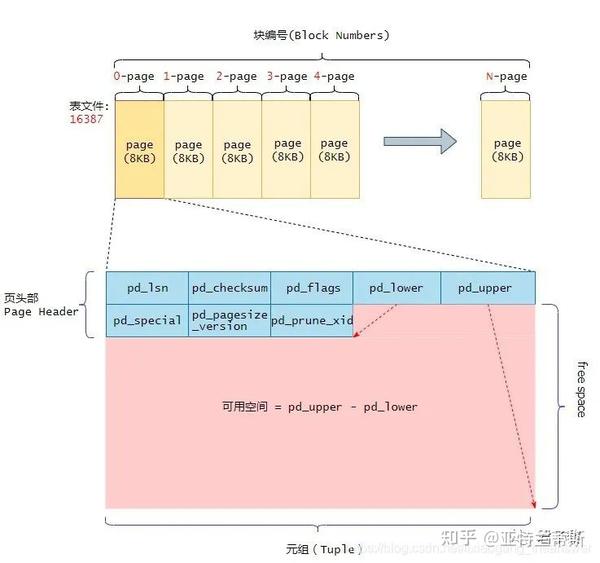
· pd_lower
指向空闲空间的开始位置。
· pd_upper
指向空闲空间的结尾。
当向表中插入数据时,postgres会分配8KB(BLCKSZ)的内存空间。此时的8KB,除了页的头部数据占用的24字节外,其余的空间都是可用于存储元组的(当然行指针也有占用空间)。如下图所示,该图是刚好分配好8KB大小的内存空间和页头占用的结构示意图。由于此时没有元组插入表文件中,所以pd_upper指向可用空间的末尾,而pd_lower指向页头(PageHeaderData)之后的第一个空闲空间的起始位置。pd_upper - pd_lower是该页中剩余可用的空闲空间(下图粉红色的区间为可用的空闲空间),随着元素的不断插入,pd_upper和pd_lower变量会不断地随着更新。
· pd_special
指向特殊空间的起始偏移量。该变量主要用于索引文件,对于表文件中的页,它指向页的末尾(因为对于普通的表文件,这个字段没有使用)。在索引文件的页中,它指向特殊空间的开始,这是仅有索引持有的数据区域,根据索引类型,如B-tree、GiST、GiN等,它包含特定的数据。
· pd_pagesize_version
页面大小及页面版本号。页面大小和页面版本号被打包成一个大一的uint16字段。这是由于历史原因,在PostgreSQL 7.3之前,没有页面版本号的概念,这样可以让我们假设7.3之前的数据库页面版本号是0。我们将页面版本号的大小限制为256的倍数,并将低8位留给版本号。
· pd_prune_xid
可删除的旧XID,如果没有则为零。
· pd_linp
pd_linp是极为重要的成员变量,它是一个零长度数组(Arrays of Length Zero)。当页中没有插入数据时候,它的数组元素个数是0,因此这个pd_linp也就是上图中所谓的“行指针”数组。它指向该页中的元组(也就是表记录)。其pd_linp的数据类型是:
typedef struct ItemIdData
{
unsigned lp_off:15, /* offset to tuple (from start of page) */
lp_flags:2, /* state of line pointer, see below */
lp_len:15; /* byte length of tuple */
} ItemIdData;
更多pd_linp成员的描述将在下面2.1.1.2小节中进行更加详细的描述。
注:PostgreSQL中,最小的页大小是64B,以适应页头、不透明空间和最小元组;最大只能支持32KB的页面大小。
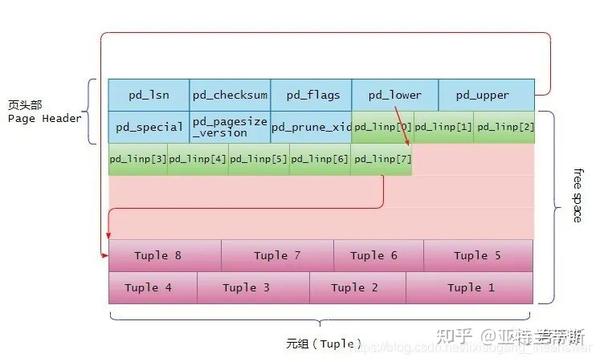
2.1.1.2 行指针(项指针)
行指针的长度为4个字节,它形成一个简单的(ItemId,行指针)数组,该数组起着元组索引的作用。每个索引编号从1开始,称为“偏移数”。当将一个新的元组添加到页的时候,新的行指针也被添加到pd_linp数组中,以指向其对应的元组。
typedef struct ItemIdData
{
unsigned lp_off:15, /* offset to tuple (from start of page) */
lp_flags:2, /* state of line pointer, see below */
lp_len:15; /* byte length of tuple */
} ItemIdData;
typedef ItemIdData *ItemId;
当不断向页中插入数据时候,其元组、行指针以及可用空间的变化如下图所示:
2.1.1.3 元组结构
在2.1.1.1和2.1.1.2两个小节中分别对页(page)中的页头数据结构和行指针的功能细节进行了较为详细的描述,接下来会对页中的元组数据结构以及其内部布局等进行分析。
对于表文件页中的元组可细分为“普通数据元组和TOAST元组”。TOAST(The Oversized-Attribute Storage Technique,超大属性存储技术)主要用于存储变长数据,当待插入元组的大小大于约为2KB(即页的1/4)时候,会自动启动TOAST技术来存储该元组。TOAST较普通元组稍加复杂些,这里主要针对普通元组文件进行说明。
元组内部可以分为三部分,分别是:堆元组头部、位图和用户存储的数据。示意图如下所示:
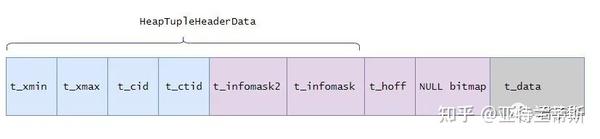
其中堆元组头部的结构定义如下:
struct HeapTupleHeaderData
{
union
{
HeapTupleFields t_heap;
DatumTupleFields t_datum;
} t_choice;
ItemPointerData t_ctid; /* current TID of this or newer tuple (or a
* speculative insertion token) */
/* Fields below here must match MinimalTupleData! */
#define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK2 2
uint16 t_infomask2; /* number of attributes + various flags */
#define FIELDNO_HEAPTUPLEHEADERDATA_INFOMASK 3
uint16 t_infomask; /* various flag bits, see below */
#define FIELDNO_HEAPTUPLEHEADERDATA_HOFF 4
uint8 t_hoff; /* sizeof header incl. bitmap, padding */
/* ^ - 23 bytes - ^ */
#define FIELDNO_HEAPTUPLEHEADERDATA_BITS 5
bits8 t_bits[FLEXIBLE_ARRAY_MEMBER]; /* bitmap of NULLs */
/* MORE DATA FOLLOWS AT END OF STRUCT */
};
其中t_choice成员变量是一个共用体数据类型。对于t_choice中的t_heap成员,它描述了当前元组的事务id、事务id等信息,如下:
typedef struct HeapTupleFields
{
TransactionId t_xmin; /* inserting xact ID */
TransactionId t_xmax; /* deleting or locking xact ID */
union
{
CommandId t_cid; /* inserting or deleting command ID, or both */
TransactionId t_xvac; /* old-style VACUUM FULL xact ID */
} t_field3;
} HeapTupleFields;
该数据类型中,t_xmin成员保存的是插入该元组的事务txid。t_xmax报错删除或是更新该元组的txid。如果尚未删除或更新过该元组,则t_xmax将设置为0,即INVALID。t_cid保留命令id(cid)。这表示了从0开始到当前事务中共执行了多少个SQL命令。比如我们在一个事务中查询了2个INSERT INTO命令,即:
'BEGIN;
INSERT INTO ... ;
INSERT INTO ... ;
COMMIT;'
那么第一次插入该元组时候,t_cid初始化为0.第二次插入次元组时候,该t_cid将被设置为1,依次类推。
t_ctid保存指向自身或是新元组的元组表示符。当该元组被更新时,该元组的t_ctid指向新的元组;否则,t_ctid指向自身。注:为了标识数据表中的元组,在元组内部使用了元组标识符(Tuple Identifile, TID), tid包含一对值,类似tid(key1, key2)。其中key1表示包含元组的页的块号,key2表示指向元组的行指针的偏移量。如下所示:
test=# select *from heap_page_items(get_raw_page('student',0));
lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid | t_data
----+--------+----------+--------+--------+--------+----------+--------+-------------+------------+--------+--------+-------+--------------------------------------------
1 | 8144 | 1 | 44 | 604154 | 0 | 0 | (0,1) | 3 | 2050 | 24 | | | \x01000000174c495849414f47414e47001c000000
(1 row)
成员t_infomask2用来表示当前元组的属性个数。t_infomask用于标识元组的当前状态,比如是否空属性、是否具有对象id、是否具有外部存储属性等等,PostgreSQL 13.2版本中,t_infomask成员具有以下状态信息:
/*
* information stored in t_infomask:
*/
#define HEAP_HASNULL 0x0001 /* has null attribute(s) */
#define HEAP_HASVARWIDTH 0x0002 /* has variable-width attribute(s) */
#define HEAP_HASEXTERNAL 0x0004 /* has external stored attribute(s) */
#define HEAP_HASOID_OLD 0x0008 /* has an object-id field */
#define HEAP_XMAX_KEYSHR_LOCK 0x0010 /* xmax is a key-shared locker */
#define HEAP_COMBOCID 0x0020 /* t_cid is a combo cid */
#define HEAP_XMAX_EXCL_LOCK 0x0040 /* xmax is exclusive locker */
#define HEAP_XMAX_LOCK_ONLY 0x0080 /* xmax, if valid, is only a locker */
/* xmax is a shared locker */
#define HEAP_XMAX_SHR_LOCK (HEAP_XMAX_EXCL_LOCK | HEAP_XMAX_KEYSHR_LOCK)
#define HEAP_LOCK_MASK (HEAP_XMAX_SHR_LOCK | HEAP_XMAX_EXCL_LOCK | \
HEAP_XMAX_KEYSHR_LOCK)
#define HEAP_XMIN_COMMITTED 0x0100 /* t_xmin committed */
#define HEAP_XMIN_INVALID 0x0200 /* t_xmin invalid/aborted */
#define HEAP_XMIN_FROZEN (HEAP_XMIN_COMMITTED|HEAP_XMIN_INVALID)
#define HEAP_XMAX_COMMITTED 0x0400 /* t_xmax committed */
#define HEAP_XMAX_INVALID 0x0800 /* t_xmax invalid/aborted */
#define HEAP_XMAX_IS_MULTI 0x1000 /* t_xmax is a MultiXactId */
#define HEAP_UPDATED 0x2000 /* this is UPDATEd version of row */
#define HEAP_MOVED_OFF 0x4000 /* moved to another place by pre-9.0
* VACUUM FULL; kept for binary
* upgrade support */
#define HEAP_MOVED_IN 0x8000 /* moved from another place by pre-9.0
* VACUUM FULL; kept for binary
* upgrade support */
#define HEAP_MOVED (HEAP_MOVED_OFF | HEAP_MOVED_IN)
#define HEAP_XACT_MASK 0xFFF0 /* visibility-related bits */
成员t_hoff标识该元组头的大小。成员t_bits数组用于标识当前元组哪些字段是空。
在读写元组头HeapTupleHeaderData时候,我们往往直接使用其HeapTupleHeader指针来进行操作。其声明如下:
/* typedefs and forward declarations for structs defined in htup_details.h */
typedef struct HeapTupleHeaderData HeapTupleHeaderData;
typedef HeapTupleHeaderData *HeapTupleHeader;
堆元组的整体数据类型声明如下,它嵌套了元组头部结构信息,另外新增了几个附加成员字段,用以描述当前元组的用户数据长度等。如下:
typedef struct HeapTupleData
{
uint32 t_len; /* length of *t_data */
ItemPointerData t_self; /* SelfItemPointer */
Oid t_tableOid; /* table the tuple came from */
#define FIELDNO_HEAPTUPLEDATA_DATA 3
HeapTupleHeader t_data; /* -> tuple header and data */
} HeapTupleData;
typedef HeapTupleData *HeapTuple;
2.1.2 pageinspect扩展查看页内容
PostgreSQL提供了一些扩展的功能,这些扩展功能的想要sql脚本都放在了share/extension/目录下,如下图示所示:
可以看到,除了pageinspect外,该目录下还有其他的附属功能脚本,比如pg_freespace(用于查看当前表或索引的页中可用的剩余空间)等。这些扩展功能使用之前需要使用SQL命令先创建:
CREATE EXTENSION pageinspect; //pageinspect --扩展功能名
若使用CREATE EXTENSION创建扩展功能时候,对应的share/extension/目录下没有该扩展功能的SQL脚本,则会报错提示当前目录没有对应的文件,如下:
ERROR: could not open extension control file "/usr/local/pg132/share/postgresql/extension/pageinspect.control": No such file or directory
2.1.2.1 查看表文件页头信息
使用page_header()函数和get_raw_page()函数结合可得到指定页的头部信息。如下所示,其中数字0表示指定表的页数。
test=# select *from page_header(get_raw_page('student', 0));
lsn | checksum | flags | lower | upper | special | pagesize | version | prune_xid
------------+----------+-------+-------+-------+---------+----------+---------+-----------
0/39620C78 | 0 | 0 | 28 | 8144 | 8192 | 8192 | 4 | 0
(1 row)
使用heap_page_items和get_raw_page可得到表元组的头部信息和数据信息,如下:
test=# select *from heap_page_items(get_raw_page('student',0));
lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid | t_data
----+--------+----------+--------+--------+--------+----------+--------+-------------+------------+--------+--------+-------+--------------------------------------------
1 | 8144 | 1 | 44 | 604154 | 0 | 0 | (0,1) | 3 | 2050 | 24 | | | \x01000000174c495849414f47414e47001c000000
(1 row)
2.2 使用工具读分析表文件内容
因为表文件中的数据都是二进制,所以在不借助工具的情况下,是无法直接查看的。因此我们需要借助工具来查看表文件中的数据内容,结合上面的介绍进行分析。在类UNIX环境上,可以使用hexdump、od命令对堆文件表中的数据进行十六进制转存,然后进行分析。当前student表中的数据仅有一条,如下:
test=# \d+ student;
Table "public.student"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+-----------------------+-----------+----------+-------------------------------------+----------+--------------+-------------
id | integer | | not null | nextval('student_id_seq'::regclass) | plain | |
name | character varying(10) | | | | extended | |
age | integer | | | | plain | |
Indexes:
"student_pkey" PRIMARY KEY, btree (id)
test=# SELECT *FROM student;
id | name | age
----+----------+-----
1 | XIAOGANG | 27
(1 row)
test=#
hexdump命令主要用来查看二进制文件的十六进制编码(当然,也可以直接vim,然后:%!xxd将其二进制数据转换为十六进制),如下所示:
[root@Thor 163898]# hexdump 16387
0000000 0000 0000 aab8 40a1 0000 0000 001c 1fd0
0000010 2000 2004 0000 0000 9fd0 0058 0000 0000
0000020 0000 0000 0000 0000 0000 0000 0000 0000
* //省略若干字节内容(全是0000, free space,未使用的内存空间)
0001fd0 b4cb 0009 0000 0000 0000 0000 0000 0000
0001fe0 0001 0003 0902 0018 0001 0000 5813 4149
0001ff0 474f 4e41 0047 0000 001b 0000 0000 0000
0002000
注:堆表文件的元组数据是从页的尾部开始存储,直到pd_upper - pd_lower的空间不足以存储元组为止。如下图中的Tuple1、Tuple2、Tuple3、Tuple4等等。
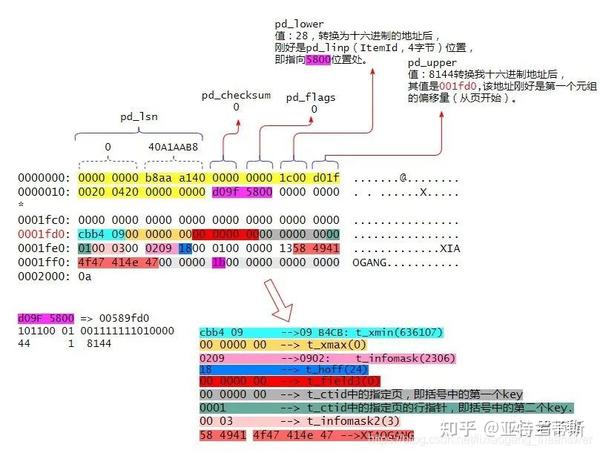
现在我们将上面hexdump显示的十六进制数据结合页头数据结构(PageHeaderData)成员列表来进行详细分析。如下图所示:
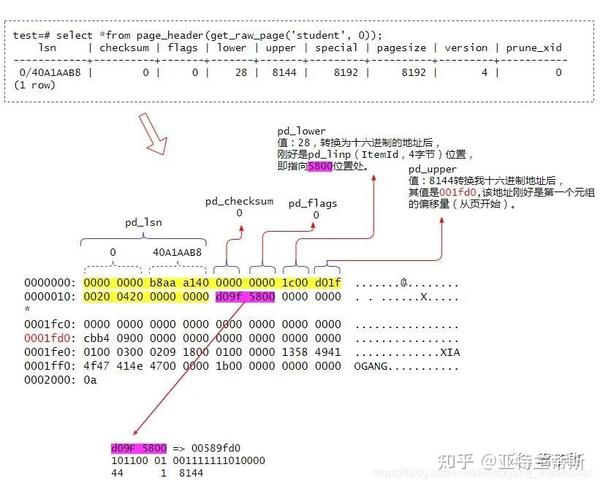
堆表文件中的页头部信息可以通过系统表page_header获取得到,其查询出来的结果和hexdump显示的十六进制数据是能够一一对应的。上图中黄色标注的24字节是页的头部(PageHeaderData),其中各成员的大小如下图所示:
上图中2000 2004 0000 0000依次对应这页头中的m_special、m_pagesize_version、pd_prune_xid。
紫色表示的4字节(d09F 5800)是指向元组的行指针pd_linp(也称为ItemId)。行指针的结构声明如下:
typedef struct ItemIdData
{
unsigned lp_off:15, /* offset to tuple (from start of page) */
lp_flags:2, /* state of line pointer, see below */
lp_len:15; /* byte length of tuple */
} ItemIdData;
第1至15位指向该元组的偏移量(从页开始)、15至17位声明当前元组的状态,这个前面有说过、17至32声明该元组的长度大小。这里之所以将hexdump展示的十六进制反过来书写是因为我当前系统架构是小端模式。经转换过后,其各值能够和pg_header表查出来的结果相吻合。说明分析是正确的。
pd_linp[0] ==== 00589FD0 //转换为二进制后是:10110001001111111010000
101100 01 001111111010000
44(字节) 1 8144(字节)
上面对页中元组的头部信息、行指针进行了详细的分析。接下来重点剖析页中行指针所指向的对应的元组数据信息。
在分析元组的结构信息时候,我们需要借助heap_page_items()函数,该函数会将元组在页内存中的分布信息详细展示出来。
test=# select *from heap_page_items(get_raw_page('student',0));
lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid | t_data
----+--------+----------+--------+--------+--------+----------+--------+-------------+------------+--------+--------+-------+--------------------------------------------
1 | 8144 | 1 | 44 | 636107 | 0 | 0 | (0,1) | 3 | 2306 | 24 | | | \x01000000135849414f47414e470000001b000000
(1 row)
test=# select *from student;
id | name | age
----+----------+-----
1 | XIAOGANG | 27
(1 row)
由于元组中字段占用的大小有严格的内存对齐要求,所以实际上可以看到各成员之间会存在一些“填充”字节数据。其对齐(必须始终是平台的MAXALIGN距离的倍数。)要求如下:
#define MAXALIGN(LEN) TYPEALIGN(MAXIMUM_ALIGNOF, (LEN))
#define TYPEALIGN(ALIGNVAL,LEN) \
(((uintptr_t) (LEN) + ((ALIGNVAL) - 1)) & ~((uintptr_t) ((ALIGNVAL) - 1)))
通过heap_page_items()函数得到结果与hexdump命令得到的数据,最终可得到该元组在页为0内存中布局详情如下图所示。下图中紫色标注的1b其值是age字段中的值27。该字段周边的0000是填充字节数据,用于保证内存对齐。
2.2.1 hexdump分析堆表文件
由于这两个命令显示的结果在不手动转换情况下,无法直接看出(需要转换)该文件中的表头结构、行指针和元组结构等数据信息。因此,出于方便,还需使用其他工具,分别是:pg_filedump和pg_hexedit。pg_filedump 和pg_hexedit 两个工具并没有附加在PostgreSQL源码中,所以源码安装的PostgreSQL中,bin目录下是没有这两个工具命令的。这两个工具有专门的pg团队在进行维护,所以你可以在github上面找到其源码,然后进行源码安装。
由于pg_hexedit工具显示的结果需要借助 wxHexEditor工具来进行展示,所以这里使用pg_filedump工具来进行分析。
2.2.2 pg_filedump
pg_filedump命令提供许多供选的参数,具体详情可使用 pg_filedump --help。该工具得到的数据比较直观,因为结果中直接给出了当前文件中的页数、行指针的起始位置,以及各页中分别指向空闲空间起始、结束位置的地址等。如下所示:
[root@Thor bin]#
[root@Thor bin]#
[root@Thor bin]#
[root@Thor bin]# ./pg_filedump -i /var/lib/pgsql/11/data/base/163898/16387
*******************************************************************
* PostgreSQL File/Block Formatted Dump Utility
*
* File: /var/lib/pgsql/11/data/base/163898/164056
* Options used: -i
*******************************************************************
Block 0 ********************************************************
<Header> -----
Block Offset: 0x00000000 Offsets: Lower 28 (0x001c)
Block: Size 8192 Version 4 Upper 8144 (0x1fd0)
LSN: logid 0 recoff 0x40a1aab8 Special 8192 (0x2000)
Items: 1 Free Space: 8116
Checksum: 0x0000 Prune XID: 0x00000000 Flags: 0x0000 ()
Length (including item array): 28
<Data> -----
Item 1 -- Length: 44 Offset: 8144 (0x1fd0) Flags: NORMAL
XMIN: 636107 XMAX: 0 CID|XVAC: 0
Block Id: 0 linp Index: 1 Attributes: 3 Size: 24
infomask: 0x0902 (HASVARWIDTH|XMIN_COMMITTED|XMAX_INVALID)
*** End of File Encountered. Last Block Read: 0 ***
[root@Thor bin]#
来源: